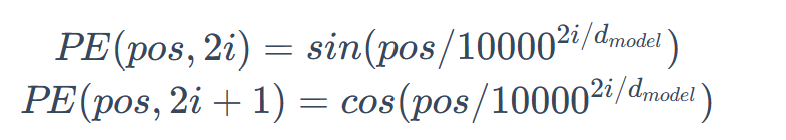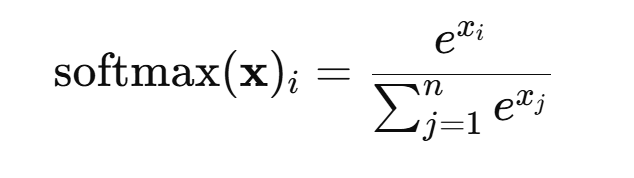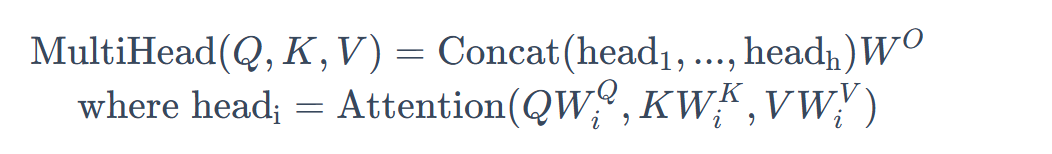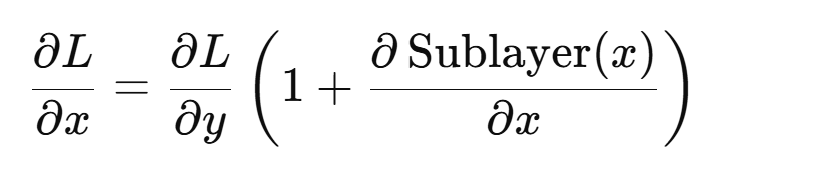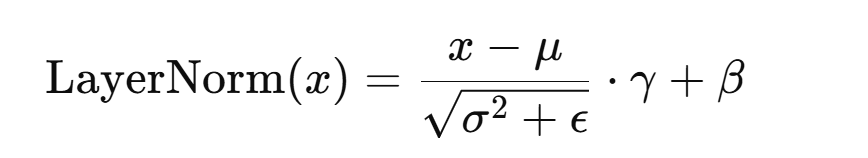最近大语言模型 (LLM)的各种应用好像都比较火热,我也来凑凑热闹浅浅研究一下AI
虽然被一堆眼花缭乱的词汇弄得有些茫然,不过还是从其最基础的架构开始学习…
从传统的机器学习,统计学习到如今的强化学习,深度学习,神经网络,包括以CV(computer vision)为起源发展起来的FNN(全连接神经网络),CNN(卷积神经网络),RNN(循环神经网络)等等,可以自行了解
它们虽风靡一时,但仍存在一些问题…
最主要的便是它们都是依序计算,限制了GPU的并行 计算能力,且难以捕捉长序列的时序关系,距离越远的输入之间的关系就越难被捕捉
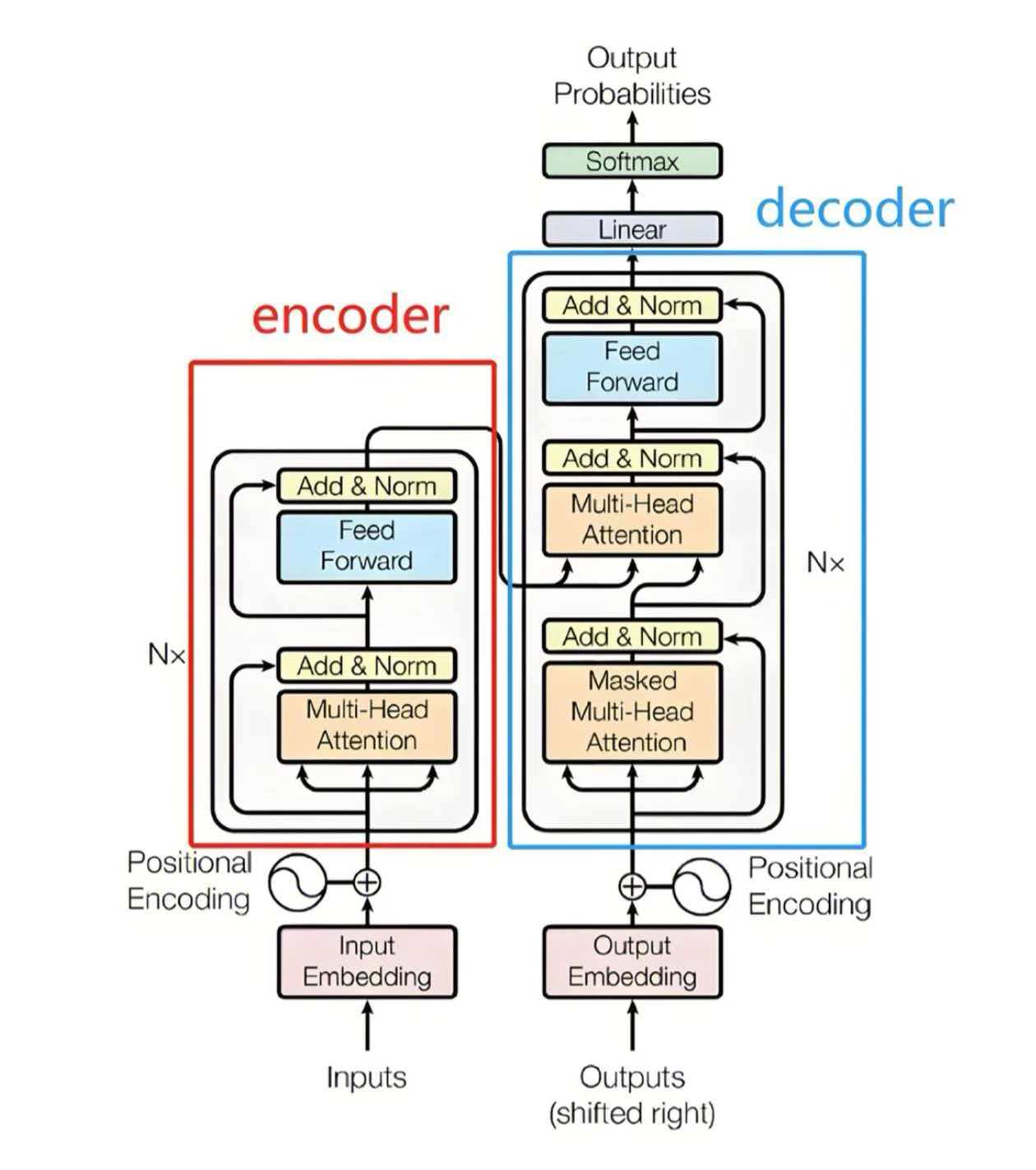
直到2017年一篇论文横空出世,attention is all you need,引入transformer架构(不是变形金刚qwq),成为了当今大语言模型的核心架构
阅读了论文,也看了很多讲解视频,学习了一下基本原理,但仍然感觉比较抽象,所以在github 的happy-llm这个项目中跟着大佬们手敲一个transformer以加深理解
原理可以自行阅读论文,看视频,也可以看看happy-llm 这个project,下面总结一下流程(我也是新手,理解有错勿喷)…
先放一下这张图
开始吧!
首先我们假设ai接收到了用户的一串输入,它肯定是看不懂文字的,只能将其转化为数字,但是若一个数字对应一个字,未免太多了,因此通常以向量 的形式来表示
具体点,这串输入被tokenizer分为一个个token(最小片段),并有着各自的token ID,通过查询词嵌入矩阵 (embedding matrix),每个token ID会被映射为一个固定维度的向量表示,即token embedding(词嵌入),这是根据大量数据的训练得来的,此时意思相近的矩阵会在如点积这类相似度计算上表现为相近,例如kobe和bryant相近(开玩笑),或者经典的like woman - man + king = queen
代码实现
1 2 3 self .tok_embeddings = nn.Embedding(args.vocab_size,args.dim)
此时文字包含了语义信息 ,但是却没有位置信息,我爱你可以被理解为你爱我,但,这可能吗…(说好的幸福呢…)
好了不扯了,那么因此要加上位置信息 对吧,采用一种很神秘的形式(PE positional embedding),跟着数学公式大致推导了一番,理解理解得了
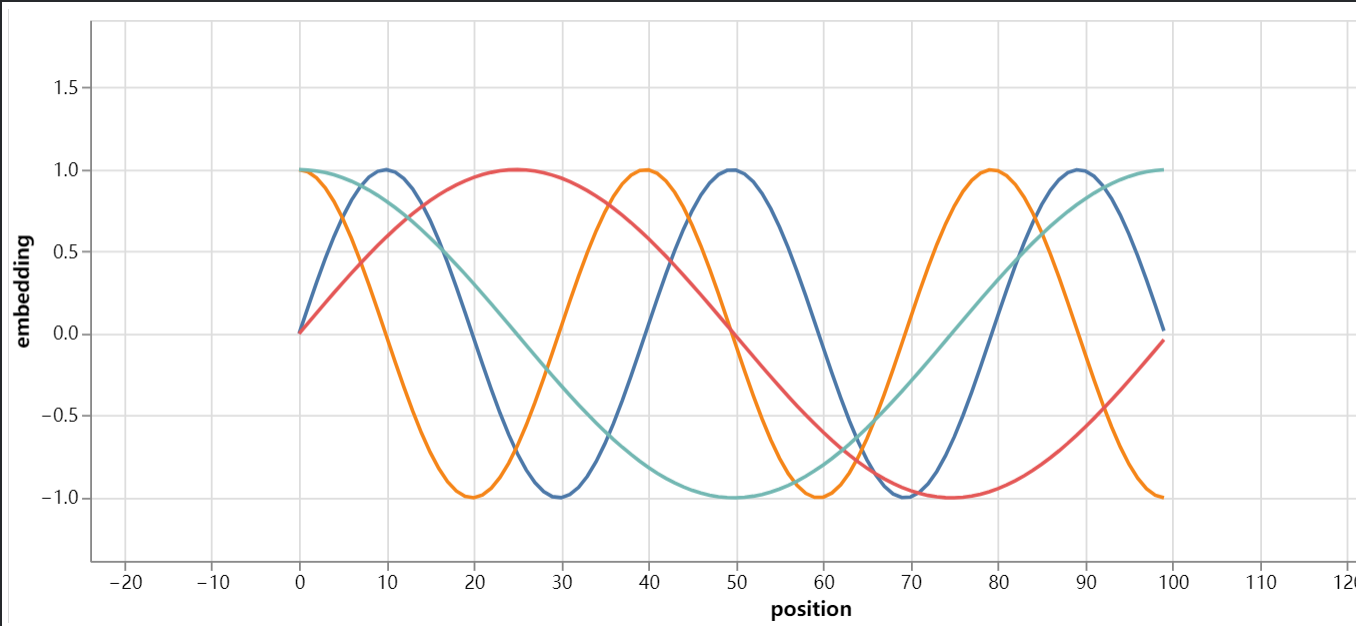
字有点丑,不要介意,证明的也比较抽象(还是去看happy-llm原文吧),总之这样我们就给token加上了位置信息,而且根据三角函数的一些性质,计算也是比较方便的,可以看到
效果还是很不错的!
numpy与pytorch的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import numpy as npimport matplotlib.pyplot as pltdef PositionEncoding (seq_len,d_model,n=10000 ):for k in range (seq_len):for i in np.arange(int (d_model/2 )):2 *i/d_model)2 *i] = np.sin(k/denominator)2 *i+1 ] = np.cos(k/denominator)return P4 ,d_model=4 ,n=100 )print (P)class PositionEncoding (nn.Module):def __init__ (self,args ):super (PositionEncoding,self ).__init__()0 ,args.block_size).unsqueeze(1 )0 ,args.n_embd,2 ) * -(math.log(10000.0 ) / args.n_embd)0 ::2 ] = torch.sin(position * div_term)1 ::2 ] = torch.cos(position * div_term)0 )self .register_buffer("pe" ,pe)def forward (self,x ):self .pe[:, : x.size(1 )].requires_grad_(False )return x
此时有了语义信息和位置信息,却没有上下文信息 ,即,词与词之间的关联
因此接下便是核心部分,attention is all you need,所谓注意力机制,源于这个经典公式
$$ \text{attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
q代表query,k代表key,v代表value
还是简单解释一下吧,例如,james is crab(随便举个例子)这句句子,被分为token A,B,C,分别是james,is,crab
每个token都有自己的q,k,v
crab的q类似于”我(crab)现在需要从上下文中获取什么信息?”
而每个token的key类似于”我这个token能回答什么问题?”
比如token A,我是一个人名
token B,我表示一种判断
v类似”如果你关注我,我真正传递给你的信息”,即,实际被加权汇总的内容
token C的q与每个token的k相乘(向量点积),然后为防止数值过大除以dim的平方根,得到一系列logits(分数),此时,显然james的分数最高,is次之,最后才是crab本身,代表”为了理解crab,我最该关注james”
最后通过softmax转换为一个和为1 的概率分布,再用该概率对所有token的v进行加权求和,得到crab的新的包含上下文信息 的向量表示,类似于”作为james的某种比喻存在的crab”,这样我们就使得crab注意到了james,有了上下文含义,是不是很奇妙
而每个q,k,v分别由原本的向量与权重矩阵Wq,Wk,Wv相乘得来,这些权重矩阵便是训练的核心,初始先随机,然后根据反向传播,梯度下降不断调整便是,不再赘述…
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def attention (query, key, value, dropout=None ):''' args: query: 查询值矩阵 key: 键值矩阵 value: 真值矩阵 ''' 1 )2 , -1 )) / math.sqrt(d_k)1 )if dropout is not None :return torch.matmul(p_attn, value), p_attn
transformer的注意力机制又包括encoder的自注意力机制 与decoder的掩码自注意力机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 ,args.max_seq_len,args.max_seq_len), float ("-inf" ))1 )float (), dim=-1 ).type_as(xq)
自注意力比较好理解,就不解释了,掩码自注意力机制 可以理解为将矩阵的上三角部分都设置为负无穷,下三角部分均为0,在与注意力分数求和并经过softmax后,上三角部分便变为了0(即被masked),因此在每一行的输入中,模型都只能看到前一个token,并以此预测下一个token,而且可以并行 地计算
但是一次注意力计算只能拟合一种相关关系,单一的注意力机制很难全面拟合语句序列里的相关关系。因此transformer使用了多头注意力机制(Multi-Head Attention),即同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系,将最后的多次结果拼接起来作为最后的输出,即可更全面深入地拟合语言信息
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 import torch.nn as nnimport torchclass MultiHeadAttention (nn.Module):def __init__ (self,args:ModelArgs,is_causal=False ):super ().__init__()assert args.dim % args.n_heads == 0 self .head_dim = args.dim // args.n_headsself .n_heads = args.n_headsself .wq = nn.Linear(args.n_embd, self .n_heads * self .head_dim, bias=False )self .wk = nn.Linear(args.n_embd, self .n_heads * self .head_dim, bias=False )self .wv = nn.Linear(args.n_embd, self .n_heads * self .head_dim, bias=False )self .wo = nn.Linear(self .n_heads * self .head_dim, bias = False )self .attn_dropout = nn.Dropout(args.dropout)self .resid_dropout = nn.Dropout(args.dropout)self .is_causal = is_causalif is_causal:1 ,1 ,args.max_seq_len,args.max_seq_len),float ("-inf" ))1 )self .register_buffer("mask" ,mask)def forward (self,q:torch.Tensor,k:torch.Tensor,v:torch.Tensor ):self .wq(q),self .wk(k),self .wv(v)self .n_heads,self .head_dim)self .n_heads,self .head_dim)self .n_heads,self .head_dim)1 ,2 )1 ,2 )1 ,2 )2 ,3 )) / math.sqrt(self .head_dim)if self .is_causal:assert hasattr (self ,'mask' )self .mask[:,:,:seqlen,:seqlen]float (),dim=-1 ).type_as(xq)self .attn_dropout(scores)1 ,2 ).contiguous().view(bsz,seqlen,-1 )self .wo(output)self .resid_dropout(output)return output
此时通过attention我们得到了包含语义,位置,上下文信息的token向量表示,但是不管多复杂,这些都是线性的,不能做复杂的非线性特征提取 ,因此需要加入一层FNN(前馈神经网络),引入非线性(激活函数),增强模型表达能力,类似于传统MLP
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MLP (nn.Module):def __init__ ()super .__init__()self .w1 = nn.Linear(dim,hidden_dim,bias=False )self .w2 = nn.Linear(hidden_dim,dim,bias=False )self .dropout = nn.Dropout(dropout)def forward (self,x ):return self .dropout(self .w2(F.relu(self .w1(x))))
随着神经网络层数的不断叠加,在反向传播的过程中,根据链式法则 ,梯度会不断与各层的导数相乘。当这些导数的模长期大于 1或小于 1时,梯度便会呈指数级增长或衰减,从而分别引发梯度爆炸 或梯度消失 问题,使得深层网络难以稳定训练,而add&norm就是在解决这个问题
其中,add代表残差连接 (residual connection)
y = x + Sublayer(x)
在反向传播时,即使子层本身的梯度很小或很大,梯度仍然可以通过残差路径(Sublayer )直接传递,从而有效缓解梯度消失和梯度爆炸的问题,并使深层网络更容易优化,毕竟x的导数永远是1,使得梯度在传播过程中至少保留一条不发生缩放的通路!
从数学角度看,设L为损失函数:
即使子层的梯度趋近于0,梯度仍然可以通过恒等映射项1直接回传,从而避免梯度完全消失;而当子层梯度过大时,残差结构也能在一定程度上缓冲梯度的剧烈变化,使训练过程更加稳定,这也是ai发展中里程碑式的一层!
稍微有点抽象,可以多理解理解…
代码实现:
1 2 3 4 self .attentiom.forward(self .attention_norm(x))self .feed_forward.forward(self .fnn_norm(h))
而norm通常采用layer norm(batch norm我不会,不讲了!)
对每个token的特征维度进行归一化处理 ,使其均值为0,方差为1,稳定各层的激活分布,防止数值随着层数加深而漂移,提高训练过程的稳定性和收敛速度
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class LayerNorm (nn.Module):def __init__ (self,features,eps=1e-6 ):super .__init__()self .a_2 = nn.Parameter(torch.ones(features))self .b_2 = nn.Parameter(torch.zeros(features))self .eps = epsdef forward (self,x ):1 ,keepdim=True ) 1 ,keepdim=True ) return self .a_2 * (x-mean) / (std+self .eps) + self .b_2
将这些串联起来,我们就能写出encoder layer和decoder layer了,而n个这样的layer便组成了完整的encoder和decoder!
代码如下,需要注意一些细节,自己注意一下吧,毕竟,attention is all you need!…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 class EncoderLayer (nn.Module):def __init__ (self,args ):super .__init__()self .attention_norm = Layernorm(args.n_embd)self .attention = MultiHeadAttention(args,is_causal=False )self .fnn_norm = LayerNorm(args,n_embd)self .feed_forward = MLP(args.dim,args.dim,dropout)def forward (self,x ):self .attention_norm(x)self .attention_forward(norm_x,norm_x,norm_x)self .feed_forward.forward(self .fnn_norm(h))return outclass Encoder (nn.Module):def __init__ (self,args ):super (Encoder,self ).__init__()self .layers = nn.ModuleList([EncoderLayer(args) for _ in range (args.n_layer)])self .norm = LayerNorm(args.n_embd)def forward (self,x ):for layer in self .layers:return self .norm(x)class DecoderLayer (nn.Module):def __init__ (self,args ):super ().__init__()self .attention_norm_1 = LayerNorm(args.n_embd)self .mask_attention = MultiHeadAttention(args,is_causal=True )self .attention_norm_2 = LayerNorm(args.n_embd)self .attention = MultiHeadAttention(args,is_causal=False )self .fnn_norm = LayerNorm(args.n_embd)self .feed_forward = MLP(args.dim,args.dim,dropout)def forward (self,x,enc_out ):self .attention_norm_1(x)self .mask_attention.forward(norm_x,norm_x,norm_x)self .attention_norm_2(x)self .attention.forward(norm_x,enc_out,enc_out)self .feed_forward.forward(self .fnn_norm(h))return outclass Decoder (nn.Module):def __init__ (self,args ):super (Decoder,self ).__init__()self .layers = nn.ModuleList([DecoderLayer(args) for _ in range (args.n_layer)])self .norm = LayerNorm(args.n_embd)def forward (self,x,enc_out ):for layer in self .layers:return self .norm(x)
最后把所有的都结合起来,合成我们的transformer!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 class Transformer (nn.Module):'''整体模型''' def __init__ (self,args ):super ().__init__()assert args.vocab_size is not None assert args.block_size is not None self .args = argsself .transformer = nn.ModuleDict(dict (self .lm_head = nn.Linear(args.n_embd,args.vocab_size,bias=False )self .apply(self ._init_weights)print ("number of parameters: %.2fM" % (self .get_num_params()/1e6 ,))'''统计所有参数的数量''' def get_num_params (self,non_embedding=False ):sum (p.numel() for p in self .parameters())if non_embedding:self .transformer.wte.weight.numel()return n_params'''初始化权重''' def _init_weights (self,module ):if isinstance (module,nn.Linear):0.0 ,std=0.02 )if module.bias is not None :elif isinstance (module,nn.Embedding):0.0 ,std=0.02 )'''前向计算函数''' def forward (self,idx,targets=None ):assert t <= self .args.block_size, f"不能计算该序列,该序列长度为{t} ,最大序列长度只有{self.args.block_size} " print ("idx" ,idx.size())self .transformer.wte(idx)print ("tok_emb" ,tok_emb.size())self .transformer.wpe(tok_emb)self .transformer.drop(pos_emb)print ("x after wpe : " ,x.size())self .transformer.encoder(x)print ("enc_out : " ,enc_out.size())self .transformer.decoder(x,enc_out)print ("x after decoder : " ,x.size())if targets is not None :self .lm_head(x)1 ,logits.size(-1 )),targets.view(-1 ),ignore_idx=-1 )else :self .lm_head(x[:, [-1 ], :]) None return logits, loss
实不相瞒,这些代码都是我手敲的,虽然注释是复制来的,总之,hands-on!
最后,AI时代,学习ai,理解ai,运用ai,让其成为你的工具,而非陷入ai是不是会取代人类的焦虑,思索…
累了,先打把瓦!
感谢阅读,生活愉快!